。为此,研究者针对这一新任务专门建立了 Video Story 数据集。该数据集包含四种常见而复杂的事件(生日、露营、圣诞、婚礼),通过关键字检索从 Youtube 上检索下载,最后手动选择 105 个在事件内部和不同事件之间都有足够差异性的视频。这些视频的故事通过亚马逊劳务众包平台 Amazon Mechanical Turk 收集。故事的选择必须满足以下三个条件:(1)至少包含 8 个句子;(2)每个句子至少包含 6 个单词;(3)故事内容要连贯,并合视频内容契合。最后研究者请工作人员针对每个故事中每个句子,标注其在视频中的开始时间和结束时间。最终,研究者收集了 529 个故事。

图|Video Story 与其他现存数据集的比较。
研究者在新数据集上对新模型和目前效果最好的模型进行了评估和比较,新模型均取得了更优的结果。
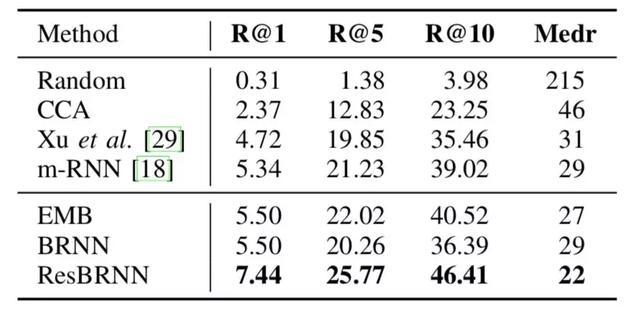
图|多模态嵌入评估:以一系列视频片段作为查询条件,检索得到一个句子序列。R@K 的数值越高,Medr 的数值越低表示效果越好
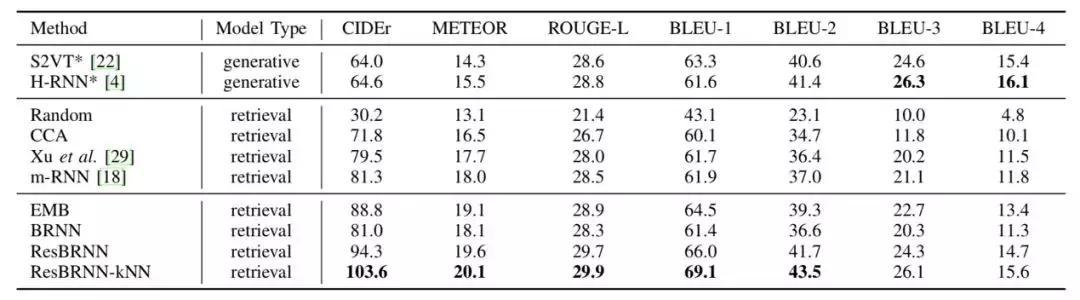
图|Video Story 数据集上,确定视频片段条件下不同模型的故事生成结果评估。ResBRNN-KNN 优势明显。
图|Video Story 数据集上的故事生成评估结果(针对对模型第二部分)。实验中,视频片段由各个模型自行提取,根据视频片段检索句子的方式固定。Narrator(旁白模型)各项指标均效果更佳。
不过,该模型目前还有很大的局限性。例如,生成故事的句子只能在数据集中检索。研究者表示,在接下来的工作中,他们将使用更多野生的句子来扩展故事的多样性,同时使用一些自然语言处理的方法使句子之间的的衔接更加自然。
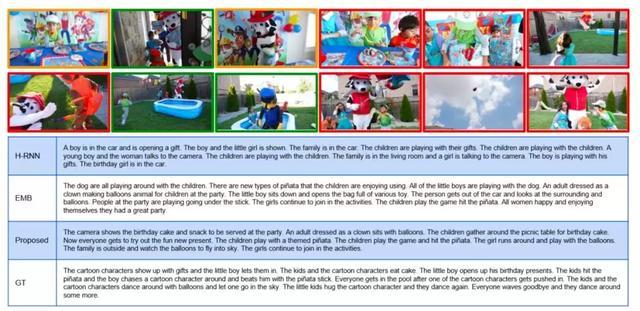
图|不同模型生成的故事举例。Proposed 为研究者提出的新模型,GT 为作为参照的标准答案。绿色框为 GT 选择的重要视频片段,黄色框新模型选择的重要视频片段。红色框为二者共同选中的视频片段。